La figura è anche disponibile in postscript come boot-lj.ps.
Ristampato con il permesso del Linux Journal
Questo articolo descrive i passi compiuti per avviare il kernel di Linux. Benché questo tipo di informazioni non sia rilevante per la funzionalità del sistema, risulta interessante vedere come le diverse architetture eseguono la fase di "boot".
Un computer è un apparato molto complesso, ed il suo sistema operativo è uno strumento elaborato che nasconde le complessità hardware per fornire un ambiente semplice e standardizzato all'utente finale. All'accensione del sistema, comunque, il software di sistema deve lavorare in un ambiente limitato, e deve caricare il kernel usando questo ambiente dalle scarse funzionalità. Di seguito viene descritta la fase di boot per tre diverse piattaforme: l'antiquato PC e i più recenti calcolatori basati su Alpha e Sparc. Il PC occuperà la maggior parte dello spazio in questo articolo perché è ancora la piattaforma più diffusa, ed anche perché è quella più difficile da avviare. Purtroppo in questo articolo del Kernel Korner non troverete alcun codice d'esempio, perché il linguaggio Assembly è diverso su ciascuna piattaforma ed è di difficile comprensione per la maggior parte dei lettori.
Solitamente il firmware verifica che l'hardware lavori correttamente, recupera una parte del kernel dalla memoria di massa e lo esegue. Questa prima parte del kernel deve caricare la parte rimanente ed inizializzare tutto il sistema. In questo articolo non tratterò le problematiche del firmware, e mi limiterò a considerare il codice del kernel, il cui sorgente è distribuito all'interno di Linux.
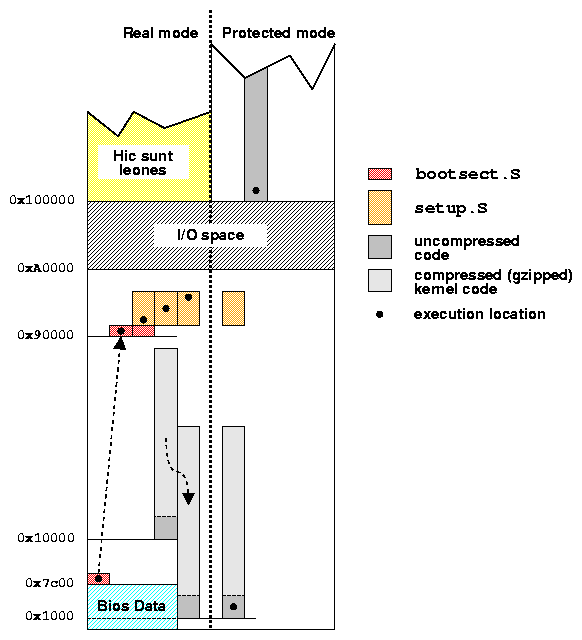
Per rendere le cose più difficili, il firmware del PC può caricare solo mezzo kilobyte di codice, e stabilisce la sua configurazione di memoria prima del caricamento di questo primo settore. Qualunque sia il supporto di memorizzazione usato per il boot, il primo settore della partizione di boot viene caricato in memoria all'indirizzo 0x7c00, dove l'esecuzione inizia. Quello che succede a 0x7c00 dipende dal boot loader usato. Di seguito analizzeremo tre situazioni: nessun boot loader, lilo, loadlin.
Il file zImage è l'immagine compressa del kernel e si trova in arch/i386/boot dopo aver compilato il kernel con il comando make zImage o make boot (il secondo comando è quello che preferisco, perché funziona anche sulle altre piattaforme). Se abbiamo costruito una "big zImage" invece, il file si chiama bzImage e si trova nella stessa directory.
Avviare un kernel x86 è un compito complesso a causa del limite imposto alla memoria disponibile (in modalità reale. Il kernel di Linux cerca di massimizzare l'uso dei 640 kB bassi sposandosi più volte all'interno della memoria. Ma vediamo in dettaglio i passi compiuti da un kernel zImage; i seguenti nomi di file sono tutti relativi ad arch/i386/boot.
La figura è anche disponibile in postscript come
boot-lj.ps.
I passi descritti in precedenza valgono nell'assunzione che il kernel compresso non occupi più di mezzo mega. Bench´ questa ipotesi sia realizzata nella maggior parte dei casi, un sistema pieno di device driver e di filesystem compilati staticamente nel kernel può tranquillamente eccedere questo limite (questo sottolinea ancora una volta l'importanza della modularizzazione del kernel). Ad esempio, il limite può venir superato dai dischi di installazione del sistema: questi kernel devono contenere molti driver e superano facilmente il mezzo mega. Per poter avviare sistemi di queste dimensioni occorre qualche nuovo trucco. La soluzione adottata si chiama bzImage, ed è stata introdotta dalla versione 1.3.73 del kernel.
Un kernel bzImage viene generato dal comando "make bzImage", invocato dalla directory principale dei sorgenti del kernel. Questo tipo di immagine del kernel si avvia in modo molto simile alla zImage, con alcune piccole differenze:
In pratica, Lilo usa i servizi del BIOS per caricare i singoli settori dal disco e poi salta a setup.S. In altre parole, Lilo sistema le cose in memoria come fa bootsect.S per il raw kenrel; in questo modo il meccanismo di avvio tradizionale può essere completato senza problemi. Lilo è anche in grado di gestire la linea di comando del kernel e questa è già una buona ragione per evitare di avviare il raw kernel dal floppy.
Per avviare una bzImage tramite Lilo, è necessario disporre almeno della versione 18 di Lilo. Versioni più vecchie non sono in grado di caricare segmenti di codice in memoria alta, operazione necessaria per caricare immagini grosse.
Il principale svantaggio di Lilo sta nel suo uso del BIOS per caricare il sistema. Questo obbliga ad avere il kernel e altri file rilevanti in dischi che siano visti dal BIOS, e all'interno di questi solo nei primi 1024 cilindri (i BIOS più recenti aggirano questo limite giocando sporco con i parametri del disco, ma questo comporta che la tabella delle partizioni non rispecchi la geometria del disco: questo dischi non potranno più essere usati su calcolatori più vecchi). Come si vede, usando il firmware dei PC ci si rende facilmente conto di quanto tale architettura sia obsoleta.
Anche chi non usa Lilo, può apprezzare i file di documentazione distribuiti con il suo codice sorgente. Essi contengono molte informazioni interessanti sul processo di boot del PC e spiegano come fronteggiare quasi tutte le situazioni possibili.
La versione 1.6 del programma e le successive sono in grado di caricare immagini bzImage.
Loadlin è in grado di passare una linea di comando al kernel e per questo è flessibile quanto Lilo; la maggior parte delle volte un utente di Loadlin finirà per scrivere un file linux.bat che passi per passare una linea del comando completa a Loadlin quando il comando linux viene invocato.
Loadlin può anche essere usato per trasformare un qualunque PC connesso in rete in una macchina Linux: a questo fine è solo necessario disporre di un'immagine del kernel predisposta per montare la "partizione di root" via NFS, l'eseguibile Loadlin ed un file linux.bat che contenga i corretti indirizzi Internet. Ovviamente serve anche un server NFS correttamente configurato, ma ogni macchina Linux può adempire questo compito. Per esempio, la seguente linea di comando commuta il PC della mia ragazza alfred.unipv.it in una workstation:
loadlin c:\zimage rw nfsroot=/usr/root/alfred \ nfsaddrs=193.204.35.117:193.204.35.110:193.204.35.254:255.255.255.0:alfred.unipv.it
Personalmente non credo che qualcuno avrà mai bisogno di modificare il codice di boot, in quanto le cose diventano molto più interessanti quando il sistema è completamente attivo: a quel punto si possono sfruttare tutte le potenzialità del microprocessore e tutta la RAM disponibile senza impazzire con problemi troppo di basso livello.
Dopo aver compiuto il solito riconoscimento dei dispositivi, il firmware visualizza un menu di boot che permette di scegliere cosa avviare. Il firmware è in grado di leggere una partizione del disco (ma solo una partizione FAT), in questo modo l'utente è in grado di avviare un file, senza bisogno di smanettare con il boot sector e dover costruire una mappa dei blocchi del disco.
Il file che viene avviato è di solito linload.exe, il quale carica Milo (il "Mini Loader", il cui nome è uno scherzoso riferimento alla dimensione del programma). Per poter avviare Linux tramite il firmware ARC occorre avere una piccola partizione FAT sul disco rigido, per contenere linload.exe e Milo. Il kernel Linux non ha comunque bisogno di avere accesso alla partizione, a meno che non si debba aggiornare Milo, per cui il supporto per il filesystem FAT può essere lasciato fuori dal kernel senza per questo avere problemi.
In pratica, l'utente può scegliere tra diverse possibilità: il menu di boot può essere configurato per avviare Linux di default, e Milo può addirittura essere trasferito nella memoria flash della macchina, in modo da poter fare a meno della partizione FAT. In ogni caso, alla fine il controllo viene passato a Milo.
Il programma Milo è in qualche modo una versione ridotta del kernel Linux: contiene gli stessi device driver di Linux ed il supporto per alcuni filesystem; a differenza del kernel però non supporta la gestione dei processi e include il codice per l'inizializzazione dell'Alpha. Milo è in grado di impostare ed attivare la memoria virtuale, e può caricare un file sia da una partizione ext2 che da un disco iso9660. Il "file" in questione viene caricato all'indirizzo virtuale 0xfffffc0000300000 e viene eseguito. L'indirizzo virtuale usato è quello dove deve girare il kernel Linux: è improbabile che Milo sia usato per caricare qualcosa che non sia Linux, con l'eccezione del programma fmu (flash management utility) usato per salvare Milo nella flash ROM. fmu viene compilato per partire dallo stesso indirizzo virtuale del kernel ed è distribuito insieme a Milo).
E` interessante notare che Milo include anche un piccolo emulatore 386 ed alcune funzionalità del BIOS del PC. Questo supporto è necessario per eseguire l'autoinizializzazione delle periferiche ISA/PCI (le schede PCI, sebbene pretendano di essere indipendenti dal microprocessore, usano il codice macchina Intel nelle loro ROM).
Ma, se Milo fa tutto di questo, cosa è lasciato al kernel Linux?
Molto poco, in effetti. Il primo codice del kernel ad essere eseguito in Linux-Alpha è arch/alpha/kernel/head.S, il quale no fa altro che impostare alcuni puntatori e saltare a start_kernel(). In effetti, kernel/head.S per Alpha è molto piè corto dell'equivalente sorgente per x86.
Per chi non vuole usare Milo c'è un'altra alternativa, anche se non molto conveniente. In arch/alpha/boot risiedono i sorgenti di un "raw loader" che viene compilato usando il comando "make rawboot" dalla directory principale dei sorgenti Linux. Il programma è in grado di caricare un file da una regione sequenziale di una periferica (il floppy o il disco rigido) usando le chiamate del firmware.
In pratica, il raw loader svolge un compito simile a quello che bootsect.S svolge per la piattaforma PC, e questo obbliga a copiare il kernel su di un floppy o una partizione raw. Dovrebbe essere evidente come non ci siano veri motivi per provare questa tecnica, che è piuttosto complessa e non offre la flessibilità offerta da Milo. Personalmente non so neppure se questo loader funzioni ancora: il "PALcode" usato da Linux è esportato da Milo ed è diverso da quello ha esportato dal firmware ARC. Il PALcode è una libreria di funzioni di basso livello, usata dai microprocessori Alpha per implementare la paginazione e altre operazioni di basso livello. Se il PALcode attivo implementa operazioni diverse da quelle che il software si aspetta, il sistema non può funzionare.
L'utente vede che il firmware carica un programma e lo esegue, il programma a sua volta può recuperare un file da una partizione del disco e decomprimerlo. Il "programma" in questione si chiama Silo, e può leggere un file sia da partizioni ext2 che ufs (SunOS, Solaris). A differenza di Milo (e similmente a Lilo), Silo può avviare anche un altro sistema operativo. Con Alpha non c'è bisogno questa funzionalità in quanto il firmware è già in grado di avviare diversi sistemi operativi: quando Milo esegue, la scelta è già stata fatta (ed è la Scelta Giusta).
Quando un calcolatore Sparc parte, il firmware carica un boot sector dopo aver eseguito la verifica dell'hardware e l'inizializzazione dei dispositivi. E` interessante notare come i dispositivi Sbus sono effettivamente indipendenti dalla piattaforma ed il loro programma di inizializzazione è codice Forth portabile, piuttosto che linguaggio macchina di un particolare microprocessore.
Il boot sector che viene caricato è quello che si trova in /boot/first.b nel filesystem Linux-Sparc, ed e' composta da 512 byte. Tale settore viene caricato all'indirizzo 0x4000 ed il suo ruolo è quello di recuperare dal disco /boot/second.b e metterlo all'indirizzo 0x280000 (2.5 MB); la scelta di questo indirizzo dipende dal fatto che le specifiche della Sparc richiedono che almeno 3 MB di RAM siano mappati durante la fase di boot.
Tutto il resto del lavoro viene fatto dal boot loader di secondo livello: esso è linkato con libext2.a per poter accedere alle partizioni di sistema, e può quindi caricare un'immagine del kernel dal filesystem Linux. second.b può anche decomprimere l'immagine perché include inflate.c, dal programma gzip.
Il codice di second.b utilizza un file di configurazione chiamato /etc/silo.conf, la cui struttura è molto simile al lilo.conf dei PC. Siccome il file viene letto durante la fase di boot, non occorre re-installare la mappa del kernel quando se ne aggiunge uno nuovo (a differenza di quanto si fa sul PC). Quando Silo mostra il suo prompt l'utente può di scegliere una qualsiasi immagine del kernel (o una altro sistema operativo) specificati in silo.conf, oppure si può specificare un percorso completo (una coppia device/pathname) in modo da caricare un'altra immagine di kernel senza dovere editare il file di configurazione.
Silo carica il file che viene avviata all'indirizzo 0x4000. Questo significa che il kernel deve essere più piccolo di 2.5 MB: se è più grande, Silo si rifiuterà di caricarlo per non sovrascrivere la sua propria immagine. Nessun kernel per Linux-Sparc concepibile attualmente può essere più grande di questo limite, a meno di compilarlo con "-g" per avere le informazioni di debugging disponibili. In questo caso bisogna usare il comando strip per ridurre l'immagine prima di passarla a Silo. Alla fine, Silo decomprime il kernel e lo rimappa, posizionando l'immagine all'indirizzo virtuale 0xf0004000. Il codice che viene eseguito dopo Silo è (come si può immaginare) arch/sparc/kernel/head.S. Il sorgente include tutta le tabelle di "trap" per il microprocessore ed il codice necessario per preparare il computer e chiamare start_kernel(). La versione per Sparc di head.S risulta abbastanza grande.
strart_kernel(), poi, inizializza tutti i sottosistemi dei kernel (IPC, networking, buffer cache, ecc.). Dopo aver completato l'inizializzazione, queste due linee completano la funzione:
kernel_thread(init, NULL, 0); cpu_idle(NULL);Il thread init è il processo numero 1: esso monta la partizione di root ed esegue /linuxrc se CONFIG_INITRD è stato attivato in compilazione; la funzione quindi esegue il programma init. Se init non viene trovato, allora viene eseguito /etc/rc. In generale, l'uso di /etc/rc è sconsigliato, in quanto init è molto piè flessibile di uno script di shell nel gestire la configurazione del sistema. In effetti, la versione 2.1.32 del kernel ha rimosso l'invocazione di /etc/rc come obsoleta.
Se né init né /etc/rc possono essere eseguiti, o se terminano, allora la funzione esegue /bin/sh ripetutamente (ma dalla 2.1.21 in poi la shell viene eseguita una volta solo). Questa funzionalità esiste solo come salvaguardia in caso di problemi: se l'amministratore del sistema rimuove o corrompe init per errore, o se viene tolto dal kernel il supporto per gli eseguibili a.out, dimenticandosi che il vecchio init non è stato ricompilato, allora si apprezzerà di avere almeno una shell attiva dopo aver fatto reboot.
Il kernel non ha nulla da fare dopo aver lanciato il processo numero 1, e tutto il resto è gestito nello spazio utente (da init, /etc/rc o /bin/sh).
E il processo 0? Si è visto come il cosiddetto "idle task" esegue cpu_idle(): questa funzione chiama idle() in un ciclo senza fine. La funzione idle() è dipendente dall'architettura e, solitamente, si occupa di spegnere il microprocessore per ridurre i consumi ed aumentare la durata del processore stesso.
di Alessandro Rubini traduzione di Andrea Mauro
La copia lettarale di questo articolo e la sua distribuzione con qualunque mezzo sono permesse, a condizione che questa nota sia conservata.