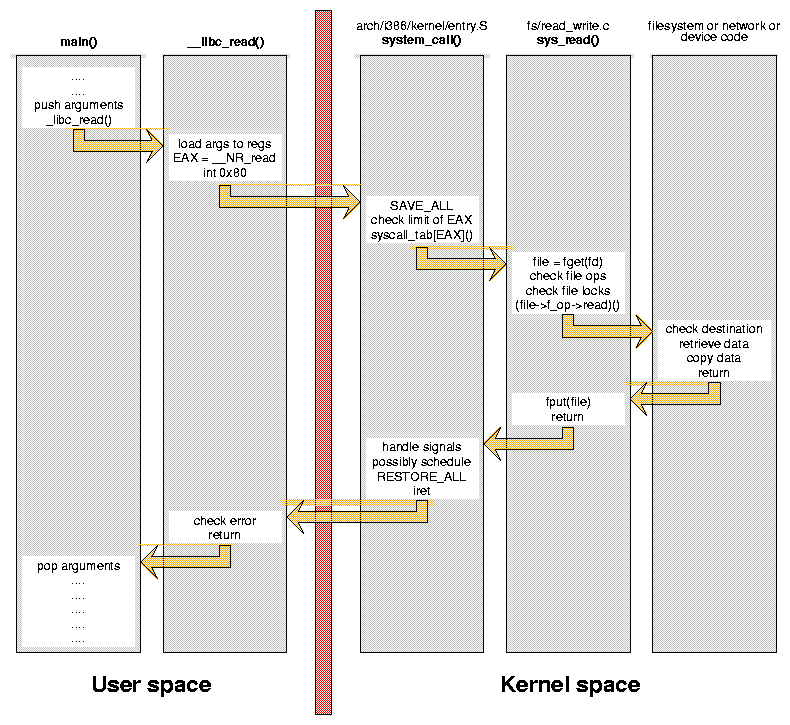
Figure 1: Steps involved in performing a call to
Reprinted with permission of Linux Magazine
by Alessandro Rubini
This article is the first step towards an understanding of how kHTTPd can take the role of a web server while never leaving kernel space.
One of the most renown features of Unix is the clear distinction between ``kernel space'' and ``user space''. System calls have always been the means through which user space programs can access kernel services. The Linux kernel implementation allows to break this clean distinction by allowing kernel code to invoke some of the system calls. This leverages the kernel's capabilities to include some of the tasks that have traditionally been reserved to user space.
To keep the discussion simple, throughout the article I'll refer to
the PC platform and to x86 processor features, disregarding for a
while any cross-platform issues. While I write this article, the
official kernel is version 2.4.0-test8 and that is what I refer to in
both the discussion and the code. Sample code is available as
ksyscall.tar.gz from here.
Please note that invoking system calls from kernel space is not in general a good thing. To the sake of maintaining, debugging and porting the code, what has always been performed in user space should not be converted to run in kernel space, unless that is absolutely necessary to meet performance or size requirements.
The gain in performance comes for avoidance of costly user-space/kernel-space transitions and associated data passing; the gain in size comes from avoidance of a separate executable with its libc and associated material.
In order to understand the speed benefits achieved by invoking
system calls from kernel space, we should first analyze the exact
steps performed by a normal system call, like
Figure 1 shows the steps involved in performing a call to
Figure 1: Steps involved in performing a call to
The image is available as PostScript ksys-figure1.ps here
A system call is implemented by a ``software interrupt'' that
transfers control to kernel code; in Linux/i386 this is ``interrupt
0x80''. The specific system call being invoked is stored in the
EAX register, abd its arguments are held in the other
processor registers. In our example, the number associated to
__NR_read, defined in
<asm/unistd.h>.
After the switch to kernel mode, the processor must save all of its
registers and dispatch execution to the proper kernel function, after
checking whether EAX is out of range. The system call we
are looking at is implemented in the
Each arrow in the figure represents a jump in CPU instruction flow, and each jump may require flushing the prefetch queue and possibly a ``cache miss'' event. Transitions between user and kernel space are especially important, as they are the most expensive in processing time and prefetch behavior.
To add real-world figures to the theoretical discussion, let's look
at the exact time lapse needed by an empty
In order to measure time lapses we can use the ``timestamp counter'' processor register. The counter, available on all kinds of Pentium processors is a 64 bit register that gets incremented at each clock tick.
To read the counter a program can invoke the rdtsc
assembly instruction. After including <asm/msr.h>,
(named after "machine specific registers"), C code can call
readtsc(low,high) to retrieve the 64 bit counter into two
32 bit variables, orreadtscl(low) to retrieve only the
lower half of the counter. We'll use the latter form, as we'll just
need subtract two values, an operation immune to 32-bit overflow if
the measured difference is less than 32 bits in size.
Listing 1, part of the usystime.c sample file, can be
used to measure the number of clock ticks the processor takes to
execute a read call. The code tries several times and only the best
figure is considered because process execution can be interrupted or
delayed because of processor scheduling, extra cache misses or other
unexpected events.
int main()
{
unsigned long ini, end, now, best, tsc;
int i;
char buffer[4];
#define measure_time(code) \
for (i = 0; i < NTRIALS; i++) { \
rdtscl(ini); \
code; \
rdtscl(end); \
now = end - ini; \
if (now < best) best = now; \
}
/* time rdtsc (i.e. no code) */
best = ~0;
measure_time( 0 );
tsc = best;
/* time an empty read() */
best = ~0;
measure_time( read(STDIN_FILENO, buffer, 0) );
/* report data */
printf("rdtsc: %li ticks\nread(): %li ticks\n",
tsc, best-tsc);
return 0;
}
Running the code on my 500MHz box reports a count of 11 ticks for
the rdtsc instruction, and 474 ticks for the empty system
call. It corresponds to aboout 0.95 microseconds. The same code
executed on a different processor takes 578 ticks (and 32 for reading
the timestamp).
; This is the pair of consecutive rdtsc after compilation
8048150: 0f 31 rdtsc
8048152: 89 c3 movl %eax,%ebx ; ini
8048154: 0f 31 rdtsc
8048156: 89 c1 movl %eax,%ecx ; end
; And this is the system call wrapped by two rdtsc
804817c: 0f 31 rdtsc
804817e: 89 c3 movl %eax,%ebx ; ini
8048180: 6a 00 pushl $0x0 ; arg 3 = 0
8048182: 8b 45 f4 movl 0xfffffff4(%ebp),%eax
8048185: 50 pushl %eax ; arg 2 = buffer
8048186: 6a 00 pushl $0x0 ; arg 1 = 0
8048188: e8 23 49 00 00 call 804cab0 <__libc_read>
804818d: 0f 31 rdtsc
804818f: 89 c1 movl %eax,%ecx ; end
Let's now consider issuing the same read system call from kernel
space. The easiest way to accomplish the task is exploiting the
definition of <asm/unistd.h> exports if [cw]KERNEL_SYSCALLS[/] is
defined. Therefore, sample code declares the macro before including any header.
Before calling the function, however, a preparing step must be performed. Like any other function that transfers data to/from user space using a user-provided pointer, the system call checks whether the provided buffer is a valid address or not. During normal operation, an address that lies in the user address range (0-3GB for standard kernel configuration) is considered valid, and an address that lies in kernel address space (3GB-4GB) is not.
If the system call is invoked from kernel space, though, we must prevent the usual check to fail, because the virtual address of our destination buffer will be in kernel space, above the 3GB mark.
The field addr_limit in the task_struct
structure is used to define the highest virtual address that is to be
considered valid; the macros
For this reasong, kernel system calls, must be wrapped by the
following code:
mm_segment_t fs;
fs = get_fs(); /* save previous value */
set_fs (get_ds()); /* use kernel limit */
/* system calls can be invoked */
set_fs(fs); /* restore before returning to user space */
There's no need to wrap each individual system call, and group of
them can occur in a row. It's important, however, that the original
``fs'' is restored before returning to user space. Otherwise, the user
program that executed this code will retain permission to overwrite
kernel memory by passing bogus pointers to further
Once equipped with these ``grossly misnamed'' tools, we can measure
the performance of a system call invoked from kernel space. The code
shown in listing 3 is part of the ksystime.c source; it
can be compiled into a module that executes the code in kernel space
(in
/* time rdtsc (i.e. no code) */
best = ~0;
measure_time( 0 );
tsc = best;
ksys_print("tsc", tsc);
/* prepare to invoke a system call */
fs = get_fs();
set_fs (get_ds());
/* time an empty read() */
best = ~0;
measure_time( read(0 /* stdin */, buffer, 0) );
ksys_print("read()", best - tsc);
/* restore fs and make insmod fail */
set_fs (fs);
return -EINVAL;
The code executed in kernel space reports 11 ticks for
Once upon a time, when Linus was playing with his new 386 PC and Linux wasn't even there, Linus said "Intel gave us the segments, let's use the segments". And he used the segments.
A ``segment register'', in i386 protected mode, acts mainly as an
index into a table of ``virtual-address descriptors'', the
``descriptor table''. And each memory access uses one of
CS (code segment, default for code fetch),
DS (data segment, default for data access),
ES, FS (extra segments, useable for data
access) as its virtual-address space descriptor.
The first implementation of the kernel-space memory map used
virtual addresses that mapped one-to-one to physical addresses. The
user-space memory map on the other hand was dictated by the binary
formats in use for executable files, and all of them use low virtual
addresses for executable and data pages. Therefore, executing system
calls required switching to a completely different memory map than the
one of user space, and this was accomplished by using different
descriptors for the memory map associated to the code and data segment
in charge in user-space and kernel-space. Since several system calls
need to access the user address space, the FS register
was reserved to hold the user memory map while in kernel space.
This explains the name of the macros:
FS.
DS.
FS, so it
will be used for data transfer instructions.
This layout of virtual memory and segment descriptors remained in
use up to version 2.0 of the kernel, included. The first great
innovation brought in by version 2.1 was the switch to a different
approach, consistent to what other platforms were already doing. The
user and the kernel descriptors now share the lower 3GB of the virtual
address space, and life is both easier and more performant.
The FS segment register has been put to rest and user
memory is now accessed by the DS register, just like
kernel memory. FS only survives in the names of a few
preprocessor macros.
You may object that the savings measured, 10%, is not as large as one may expect.
Actually, a quick look at the definition of the macro (in the
header) or at disassembled object code shows that the implementation
of <asm/unistd.h> still
calls interrupt 0x80. The kernel implementation of the system call is
not optimized for speed, and is only there for the convenience of a
few kernel needs.
It's interesting to note how code for some Linux platforms invokes
kernel system calls by directly jumping to the
But if you are really interested to get the best performance out of
your kernel system calls, the thing to do is directly invoke the
stdin). This approach to system calls invocation from
kernel space is the one used the
Listing 4 shows the code that implements this technique in the
sample module ksystime.c. The
/* use the file operation directly */
file = fget(0 /* fd */);
if (file && file->f_op && file->f_op->read) {
best = ~0;
measure_time(
file->f_op->read(file, buffer, 0, &file->f_pos)
);
ksys_print("f_op->read()", best - tsc);
}
if (file) fput(file);
The execution time of this code is reported as 175 clock ticks, 63%
(or 0.6 microseconds) less than the user space case. You may even try
to cache the two pointers being used in the call (
This is how the output of themodule looks like on my system (the
output is found in
kernel: ksystime: 11 -- tsc
kernel: ksystime: 424 -- read()
kernel: ksystime: 216 -- sys_read()
kernel: ksystime: 175 -- f_op->read()
kernel: ksystime: 173 -- cached_f_op_read()
Up to now we have collected a few figures, and found that making system calls from kernel space can significantly reduce the overhead of the system call mechanism. It's high time, in my opinion, to step back for a while and ponder over the figures we collected.
How could we still incur in 175 clock ticks of overhead associated
to the
The answer is in looking at the
Figure 2 shows the times I collected on my PC, to give an idea of
the great difference in the various

Figure 2: Times in the various
The image is available as PostScript ksys-figure2.ps here
While kernel-space system calls are an interesting tool, and
playing with them can teach a lot about kernel internals, I still
think their use should be as limited as possible. For example, a
device driver shouldn't read a configuration file using kernel-space
system calls; reading a file involves error manamegent and parsing of
file contents -- not something suited for kernel code. The best way to
feed data to device drivers is through
This column showed how kernel system calls work in order to lay
the foundations for a discussion of the
rubini@gnu.org.