Uso avanzato di Git
di Alessandro Rubini
Riprodotto con il permesso di Linux & C, Edizioni Vinco.
Il pacchetto git, scritto inizialmente da Linus Torvalds e
portato poi avanti da altri sviluppatori sotto la guida
di Junio Hamano, viene usato per la gestione
del codice sorgente di un numero sempre maggiore di progetti, dal
kernel e U-Boot a Xorg e busybox. Rientra nella
categoria dei sistemi distribuiti di controllo versione.
Una prima introduzione all'uso del pacchetto
è stata pubblicata su queste pagine
nel numero 63, a firma di Rodolfo Giometti; oggi invece vengono
presentate alcune funzionalità più avanzate, necessarie per interagire
con progetti complessi, cercando di eviscerare le idee realizzate
all'interno del
pacchetto. Il riquadro 1
riassume i sottocomandi principali di git,
come veloce riferimento per i meno esperti.
Riquadro 1 - Comandi più comuni di git
Questi sono i comandi più importanti per gli utenti git. Gli
argomenti non sono qui indicati in quanto spesso vi sono più forme d'uso,
con argomenti di tipo diverso:
- git clone: crea una copia locale di un archivio remoto
- git fetch: scarica gli aggiornamenti su di un ramo locale
- git branch: crea, rinomina, cancella i rami dell'albero
- git checkout: estrae i file relativi ad una versione o un ramo
- git add: predispone il salvataggio di uno o più file modificati
- git commit: salva nell'archivio una patch
- git rebase: sposta la base di un ramo innestandola altrove
- git log: mostra lo storico del ramo o di un file
- git diff: stampa le differenze tra versioni o rami
- git merge: riunisce due rami mantenendo la storia di entrambi
- git pull: equivalente di fetch e merge insieme
I sistemi distribuiti di controllo versione sono sempre più
diffusi, e git non è il primo né sarà di certo l'ultimo. Le
funzionalità e le idee qui descritte sono presenti in misura
variabile anche in altri pacchetti, come mercurial; il fine
di questo articolo non è dimostrare la superiorità di git ma
presentare delle soluzioni interessanti che possono essere utili
anche in altri contesti, prendendo come scusa uno
strumento che in un modo o nell'altro ha raggiunto una certa diffusione.
Per evitare ambiguità, il contenuto di una cartella non verrà mai
indicato con il termine albero, riservando tale termine alla
storia di sviluppo di un pacchetto, con tutte le sue ramificazioni.
Il problema della verificabilità
Uno dei problemi che si affrontano spesso nella gestione di grossi
progetti è l'allineamento imperfetto tra le directory di sviluppo dei
diversi programmatori. Non è inusuale eliminare completamente una
directory per ripartire da un archivio originale o un checkout
completo dal server principale del progetto. Lo stesso problema si ha
quando vi sono collisioni durante l'applicazione di una patch,
oppure per qualche disattenzione si è danneggiato il codice sorgente.
È certamente antipatico dover spostare decine o centinaia di megabyte
per ripristinare un pacchetto sorgente, ma è ancora più problematico
verificare che la propria versione sia esattamente uguale a quella di un
altro sviluppatore con cui non si possano scambiare direttamente i file.
La soluzione adottata per entrambi questi problemi sta nell'identificare
ogni
oggetto gestito da git con un codice di controllo: un numero
derivato dalla totalità dei dati associati tramite un algoritmo matematico
non invertibile. Il codice di controllo, detto in gergo hash o
message digest, caratterizza (o "riassume")
un dato o un insieme di dati, senza che sia possibile generare
altri dati che generino la stessa hash.
L'algoritmo usato in git è SHA1 (Secure hash
algorithm 1), che fornisce 160 bit di output. Tale numero
viene normalmente rappresentato come 40 cifre in base 16.
Per esempio, per raggruppare tra tutti i file COPYING
nel proprio disco quelli che sono copie conformi della stessa licenza
basta fare:
locate COPYING | xargs sha1sum | sort
In git, perciò, ogni singolo file, ogni directory e ogni
commit viene identificato dal proprio hash. Un
particolare punto nella storia di sviluppo di un pacchetto non è
quindi identificato da un numero sequenziale di versione ma da un
codice univoco di 160 bit. Un oggetto di tipo commit contiene le
modifiche apportate ai file (la "patch"), il commento esplicativo e il
codice SHA1 del commit precedente, come pure quello dell'intera
struttura
di file che rappresenta. Due programmatori che hanno lo stesso commit
sono sicuri di avere lo stesso pacchetto di sorgenti. Nelle discussioni
tecniche sulle liste è pratica comune riferirsi al codice o alle
patch tramite il loro codice SHA1, o ad una abbreviazione di esso.
Riquadro 2 - Unicità dei codice hash
I codici di message digest, tra cui i più noti sono SHA1 e MD5,
garantiscono l'unicità del codice generato su basi statistiche. Il valore
di uscita, il codice hash ha una distribuzione uniforme sullo
spazio dei valori. Ricordando che 2^10 equivale è poco più di 10^3,
c'è una possibilità su 4x10^9 (4 miliardi) che
due codici a 32 bit siano uguali, questo numero diventa dell'ordine
di 10^38 per i codici MD5 a 128 bit e di 10^48 per i codici SHA1 di 160 bit.
Anche avendo 1 milione di file, la probabilità che due qualunque di
questi abbiano lo stesso codice SHA1 è di 1 su 10^36, mentre per un
miliardo di file sale a 1 su 10^30 (10^30 è circa il numero di
granelli di sabbia che servono a formare il pianeta Terra). Difficile
dire che il codice non sia globalmente unico.
Gli algoritmi di hash sono progettati in modo che la
differenza di un solo bit nei dati di ingresso perturbi tutti i bit
nel valore di uscita, per cui in pratica per identificare un file
basta indicare le prime cifre di tali valori per avere una certa
sicurezza di non sbagliare. Perciò git accetta identificativi
abbreviati a piacere, purchè non siano ambigui all'interno del
progetto e mostra solo 7 cifre se si richiede la forma abbreviata del
codice.
Anche in un progetto con 100mila oggetti, come può essere il
kernel, la probabilità che un codice di 7 cifre (28 bit) sia ambiguo
è di uno su 2500. In questi casi il codice abbreviato serve a scegliere tra
i pochi codici già nel progetto, non serve sia globalmente unico.
Quando il codice a 7 cifre è ambiguo il programma ne mostra 8 o più,
fino a risolvere l'ambiguità -- un po' come a scuola: per identificare
un alunno basta il nome o il cognome, se c'è ambiguità si aggiunge l'altra
iniziale. Internamente però tutti i codici vengono gestiti nella loro
interezza.
Facciamo una prova, confrontando il codice SHA1 di Linux-2.6.30
estratto da un archivio git e quello del tar ufficiale,
sfruttando git cat-file per ispezionare i commit relativi:
bash$ cd linux-2.6.git
bash$ git checkout v2.6.30
HEAD is now at 07a2039... Linux 2.6.30
bash$ git cat-file commit 07a2039 | grep tree
tree 0cea46e43f0625244c3d06a71d6559e5ec5419ca
bash$ tar xjf linux-2.6.30.tar.bz2
bash$ cd linux-2.6.30
bash$ git init
bash$ git add .
bash$ git commit -m "from tar file"
Created initial commit 7a6212e: from tar file
bash$ git cat-file commit 7a6212e | grep tree
tree 0cea46e43f0625244c3d06a71d6559e5ec5419ca
Riquadro 3 - Il comando git cat-file
Poiché git memorizza tutti i suoi oggetti in formato
compresso, identificandoli in base al codice SHA1, viene fornito il
comando "git cat-file" per stampare su stdout (come il
comando cat, appunto) il contenuto di un oggetto. Il comando
riceve due argomenti: il tipo di oggetto e il codice dell'oggetto.
Per un oggetto di tipo blob il comando restituisce il contenuto
del file, mentre nel caso di un oggetto di tipo commit,
l'output è un breve testo che contiene oltre al messaggio di
log l'indicazione dell'autore, data e ora del commit in
formato Unix e i codici SHA1 di parent (il commit precedente) e
tree (la directory di file descritta da questo commit).
Questo comando non ha un'interfaccia molto amichevole (per esempio,
git cat-file di un oggetto tree restituisce un file
binario), perché fa parte degli strumenti di basso livello, utilizzati
da altri sottocomandi di git per svolgere il loro lavoro.
Nella documentazione, i comandi di basso livello come questo si
chiamano plumbing (tubature) mentre quelli pensati per l'uso
diretto da linea di comando, come quelli indicati nel
riquadro 1, si
chiamano porcelain (sanitari: l'interfaccia utente del servizio
idrico).
Come si vede, l'oggetto di tipo tree contenuto
nei due oggetti commit è lo stesso; questo basta a dimostrare
che i 400MB dati recuperati nei due modi sono identici tra loro.
Tramite "git ls-tree" è possibile verificare la rappresentazione
interna di git per tali oggetti: come in una directory Unix, l'oggetto
contiene nomi e identificativi di altri oggetti: quelli di tipo
blob sono i file e quelli di tipo tree sono
le subdirectory). Se una directory associa i nomi al
numero di inode, che è univoco all'interno del filesystem,
un oggetto tree associa i nomi ai loro hash, che sono
univoci globalmente. Il contenuto di un oggetto viene poi memorizzato
in un file il cui nome è proprio il codice SHA1 relativo. Una conseguenza
di questo approccio è che gli oggetti di git sono
immutabili: ogni modifica, anche di un solo bit, crea
un nuovo oggetto con un nuovo hash e di conseguenza un nuovo file.
Un effetto collaterale non trascurabile dell'uso massiccio di
codici hash è la facilità di firma. Se l'autore vuole firmare
una particolare versione del pacchetto software è sufficiente che
firmi il codice SHA1 che rappresenta l'intera cartella dei sorgenti;
per certificare tutta la storia di sviluppo basta
firmare l'ultimo commit che come abbiamo visto contiene al suo
interno anche il codice di tutta la directory.
La firma viene effettuata con il classico metodo
a chiave asimmetrica.
Ecco perciò che se uno sviluppatore firma
un commit, chiunque abbia sulla propria macchina lo stesso
commit o la struttura di file cui esso fa riferimento,
una volta verificata la firma ha la certezza di
avere esattamente la stessa versione dei sorgenti, anche se provengono da fonti
non fidate. Le uniche componenti che devono essere fidate sono
gli strumenti di generazione e verifica del codice SHA1, cioè git,
gpg e
altri strumenti normalmente parte del sistema operativo, cioè
normalmente pacchetti firmati dai rispettivi manutentori.
Creazione di un ramo
La differenza principale tra i sistemi distribuiti di controllo versione
e quelli centralizzati sta nella facilità dei primi di
creare nuovi rami, branch.
Personalmente usando git trovo il concetto
di ramo molto simile a quello di etichetta
(tag), e non me ne voglia chi conosce le rappresentazioni interne
dei due concetti: si può dire che un ramo è come
un'etichetta perché come il comando "git tag
v1.0" associa un nome significativo al codice SHA1
dello stato corrente dei sorgenti, anche il comando "git branch
1.0-fixes" associa allo stato attuale un nuovo nome simbolico.
Entrambi potranno essere usati in "git checkout <nome>"
per recuperare la stessa versione.
Il nome di ramo però è un'etichetta mobile: in caso vengano effettuate
modifiche e relativi commit, il tag continua ad indicare la
versione originaria mentre il nome di ramo si sposta seguendo lo sviluppo.
Salvo casi eccezionali cosiddetti detached head
qui non trattati, lo stato dei sorgenti sul disco
(la posizione head in terminologia
git) corrisponde ad un ramo dell'albero di sviluppo, perciò ogni
commit provoca la crescita di un ramo.
Il nome del ramo principale, che altri pacchetti chiamano
trunk (tronco),
è master; tale ramo viene creato al primo commit di un
nuovo progetto ma a parte questo non è trattato come un caso particolare.
Tutti i rami dell'albero sono trattati allo stesso modo e tutti possono
essere rinominati o cancellati, compreso master. Cancellare un
ramo è come cancellare un'etichetta: gli oggetti git
rimangono e si possono sempre recuperare conoscendo il loro codice
SHA1, almeno finchè non si fa pulizia, argomento qui non trattato.
Per spostarsi da un ramo all'altro si usa il comando git
checkout <branch>, ma il programma si rifiuta di
svolgere tale operazione se i file sono
stati modificati e non è stato fatto commit; in questo modo si
è tutelati da perdite di lavoro inaspettate.
L'idea che un ramo sia solo un etichetta, indipendentemente da dove e come
si è staccato dal ramo di partenza è notevole: se durante la
scrittura di codice si arriva ad un punto morto si può staccare un
ramo di sviluppo dalla storia precedente e intraprendere una strada
diversa; se tale strada si dimostra vincente si può cancellare il
ramo di partenza senza alcun effetto nefasto sul ramo in uso; cancellare
un ramo è come cancellare un'etichetta: l'effetto è solo quello di
non poter più raggiungere lo stato relativo del codice
usando un nome mnemonico. Il fatto che un nuovo ramo si fosse staccato
da quello ora rimosso non è rilevante, perché l'estremità
del ramo rimasto identifica tutta la storia dalla creazione del
progetto fino a quel punto, senza riferimento ad altri rami o a punti
di separazione.
È possibile, naturalmente, sapere in cosa un ramo si differenzia da
un altro ramo (per esempio da quello originale da cui si è separato):
poiché nessun ramo si riferisce ad altro che non sia la sua storia,
il sistema scandisce all'indietro
la storia dei due rami fino a trovare un punto comune, un
identificativo SHA1 presente in entrambi i rami. Solo da questa circostanza
si può sapere che i due rami hanno un'origine comune, che una volta
identificata serve come base per mostrare le differenze.
Tale flessibilità nella gestione dei rami porta facilmente un
programmatore ad avere decine di rami nel suo albero; occorre perciò
scegliere con attenzione il nome di ogni ramo, e ricordarsi di eliminare
o spostare in un altro albero i rami non più attivi, per non dover
faticare a tener traccia del proprio lavoro.
Riquadro 4 - Nomi di versione validi in git
Gli identificativi usati nelle righe di comando di git per
indicare i commit o gli altri oggetti possono
essere di vari tipi. I più utilizzati sono:
- il codice SHA1: una stringa di 40 cifre in base 16
- una sua abbreviazione: una stringa in base 16 non ambigua
- un nome simbolico: nome di tag o di branch
HEAD: il codice attuale, l'ultimo commit- nome^: il commit precedente nome
- nome~n: n commit all'indietro da nome
Alcuni comandi possono operare su intervalli (per esempio git log
o git diff). La forma più comune per specificare gli
intervalli è "v1..v2", che indica
tutti i commit raggiungibili da v2 ma non da v1.
Poiché ogni commit contiene il riferimento a tutta la sua storia,
"raggiungibile" indica un avo della versione indicata. Perciò
la notazione .. indica la storia da v1 a v2,
oppure dalla biforcazione fino a v2, se le versioni indicano due
rami o appartengono a rami diversi.
Pulizia e riordino del proprio codice
La persona che scrive di getto codice funzionante non è di
questa terra (ci sono alcune rare eccezioni ma gli strumenti non possono
pensare solo a loro). Inoltre, potersi dedicare ad un problema
fino a risolverlo ignorando altre questioni è un lusso che
pochi possono permettersi. Il risultato di questi limiti interni ed
esterni al programmatore è che nella pratica ciascuno sviluppa codice
in maniera disordinata: da un lato aggiunge e
toglie stampe diagnostiche e artifici simili di cui si potrebbe
vergognare, dall'altro affronta più problemi alternativamente
abbandonando ciascuno di essi prima di avere una soluzione soddisfacente,
salvo poi completarli in tempi diversi.
Il ramo di lavoro perciò
ha spesso un storia variegata:
si alternano commit relativi a problemi
diversi, ma anche l'aggiunta e la successiva rimozione di parti di
codice.
Prima di consegnare il proprio lavoro alla storia
dell'informatica, solitamente l'autore deve fare pulizia: cambiando l'ordine
relativo dei commit, accorpando diverse modifiche in una
sola patch che in un sol colpo risolva un problema o
aggiunga una funzionalità, eliminando modifiche irrilevanti.
Lo strumento che ci viene offerto da git è
il comando "git rebase -i", dove la i sta per
"interattivo". Il comando permette di riscrivere la storia
del ramo corrente, a partire dalla versione specificata. Per esempio
"git rebase -i HEAD~10" permette di riordinare, accorpare,
eliminare, gli ultimi 10 commit effettuati. Per fare questo git
apre un editor di testi contenente la lista degli ultimi
commit, uno per riga, e le istruzioni su come modificare la
storia. La procedura è ben descritta e non verrà qui ripetuta.
Chi volesse salvare lo stato del proprio lavoro prima di
avventurarsi in un riordinamento può semplicemente creare un nuovo
ramo e cambiare la storia solo di quello; in alternativa
si può tenere memoria del commit di partenza. A posteriori si può
sempre chiedere a git la differenza tra i due rami o tra la
nuova e la vecchia situazione tramite git diff.
Spostare i rami tra gli alberi: fetch, rebase, cherry-pick
Poiché tutto l'albero della storia di un pacchetto è memorizzato
nella cartella .git all'interno del pacchetto stesso, una
necessità abbastanza comune è quella di spostare i rami tra più alberi,
sia all'interno dello stesso disco sia tra macchine remote.
Per copiare gli oggetti git tra più alberi si usa il
sottocomando fetch. Lavorando sull'albero ricevente occorre
specificare sulla riga di comando il nome del ramo remoto da scaricare
e il nome del ramo locale in cui inserire gli oggetti. Il programma
recupera la storia del ramo remoto e copia localmente solo gli oggetti
che non siano già presenti. Durante la copia del ramo vengono
riprodotti localmente anche eventuali tag dell'albero remoto che si
riferiscono al ramo in questione.
Il nome indicato per il ramo locale può
esistere già; se il nome di ramo non esiste viene creato,
ramo, altrimenti viene allungato il ramo locale pregresso. In questo
caso il ramo locale deve coincidere con
la storia passata del ramo che si vuole replicare, altrimenti non sarebbe
possibile ricreare localmente gli stessi oggetti; l'errore
segnalato in questo caso è "rejected: non fast-forward": un
fetch può solo portare avanti un ramo senza modificarlo in altro modo.
Normalmente i "piccoli programmatori" tengono una copia locale dei
rami dei "grandi programmatori", sul quale viene periodicamente
effettuato il fetch per seguire lo sviluppo del pacchetto. Un ramo
locale usato per seguire un albero remoto viene chiamato remote
tracking branch, qui abbreviato in "ramo remoto"; chi lavora su
modifiche ad un progetto esterno solitamente stacca da questo ramo
remoto un nuovo ramo, locale.
Il sottocomando fetch si usa in questo modo:
git fetch id-albero-remoto ramo-origine:ramo-destinazione
L'albero remoto può essere un pathname, una cartella remota
in formato ssh oppure un URL di tipo http:// o
git://.
Si noti che tutti i rami di un albero sono locali, anche quelli "remoti".
Tutte
le informazioni di git, per scelta, sono contenute nella cartella
.git del pacchetto sorgente; un ramo è
remote tracking o meno solo in base a come si usa. È comunque possibile,
per semplificare le righe di comando da usare, specificare
in .git/config
gli argomenti predefiniti da usare per il comando fetch su
particolari rami.
Dopo aver effettuato sviluppi locali su di un ramo derivato da uno
remoto, un successivo fetch sul ramo remoto porterà ad
una biforcazione; è perciò frequentemente necessario spostare il ramo
locale in modo che si innesti sulla nuova estremità del ramo remoto. Questa
operazione di chiama rebase, e viene invocata, stando sul ramo
locale, come "git rebase <otherbranch>". L'operazione
svolta durante un rebase è la seguente: viene identificato
il punto di biforcazione del ramo corrente e di quello su cui si
sta ri-basando, si
riavvolgono tutti i commit successivi a tale separazione,
si applicano
quelli che portano dalla biforcazione alla nuova base, vengono poi
ri-applicati quelli del ramo locale, gestendo eventuali differenze.
A differenza dell'applicazione di normali patch nella nuova
situazione, durante un
rebase il sistema è in grado di contestualizzare
i commit locali all'interno della storia del codice, in modo da
ridurre notevolmente la possibilità di errori e conflitti. Gli algoritmi
utilizzati in questa fase si chiamano 3-way merge e octopus merge
e sono lo stato dell'arte della ricerca in quest'area.
Un'altra necessità abbastanza sentita dai programmatori è quella
di importare in un ramo alcune modifiche già effettuate in altri
rami. Il sottocomando cherry-pick permette di "scegliere le
ciliegine": selezionare un oggetto commit (uno alla volta)
tra tutti quelli
disponibili e applicarlo nel ramo corrente. Questo comando risulta utile
quando si abbandona lo sviluppo su di un ramo che contiene alcuni passaggi
comunque ancora utili, oppure quando si seguono rami di altri sviluppatori
dei quali si vogliono usare parti specifiche nel proprio lavoro.
Gestione di un conflitto
In tutte le situazioni di sviluppo concorrente da parte di più
persone, uno dei problemi più
comuni è la gestione di un conflitto: si ottiene un conflitto
quando si cerca di applicare una
patch ad una frammento di codice che nel frattempo è stato
modificato: le due modifiche, pur partendo dalla stessa versione
del codice, sono incompatibili e non possono essere accorpate
automaticamente. Un conflitto può succedere
anche all'interno dello stesso
albero, nelle operazioni di merge (qui non trattata)
e rebase, interattivo o meno. Una esempio di situazione di
conflitto si ha quando si cambia l'ordine di
due patch, la prima delle quali rinomina una variabile e la
seconda modifica una parte di codice che usa tale variabile:
la seconda modifica
non può essere applicata al sorgente originale, in quanto le righe di
codice da questa modificate non esistono nella versione di partenza,
che usa il vecchio nome della variabile.
In questi casi git segnala il conflitto nei suoi messaggi
e interrompe l'operazione di rebase lasciando all'interno dei
file in conflitto
i consueti marcatori <<<<<, =====
e >>>>>. L'utente in questo caso deve
risolvere manualmente il problema e poi invocare "git add"
su tali file, prima di usare "git rebase -continue".
Alternativamente si può usare "git rebase --abort" per
eliminare completamente l'operazione. Senza un esplicito git add,
il file che ha dato conflitto non viene salvato nel database di git;
risulta perciò quasi impossibile salvare file che includono i marcatori
di conflitto.
A differenza di quanto accade con CVS, usando git il
conflitto è sempre nella risoluzione di modifiche tra file già noti
al sistema, per cui non si ha mai perdita di informazione. Con CVS e
alcuni altri sistemi centralizzati, spesso si verificano
conflitti tra una versione locale e
una registrata nell'archivio centrale: il programma perciò
modifica la versione locale
con l'introduzione dei marcatori di conflitto e l'utente si trova
a non avere più una versione intatta dei suoi dati, che deve
ricostruire. In git invece il file locale modificato
con i marcatori è una versione temporanea, che tra l'altro è
considerata discendente da due file genitori, entrambi noti a git.
Per questo motivo il comando "git
diff" in questa situazione usa un formato diff diverso, per
indicare separatamente le differenze nel
file attualmente sul disco rispetto a ciascuno dei due
genitori. Non è immediato prendere confidenza con questo formato, ma dopo
una po' di pratica può rivelarsi estremamente utile.
Anche nella gestione dei conflitti, il fatto che git
registri tutta la storia tramite oggetti non modificabili ci viene in
aiuto: persino nelle situazioni più tragiche di corruzione
dei propri sorgenti è possibile
ripescare una versione nota da cui ripartire, ignorando il pasticcio
che si è combinato. Se si è tentato un merge o un rebase
fiduciosi del suo successo e non si ha tempo di gestire i conflitti, basta
rifare checkout di uno dei due rami di partenza, che sono
stati preservati: i file in conflitto vengono semplicemente scartati insieme
a quelli in cui l'operazione ha avuto successo.
Talvolta capita di modificare erroneamente un ramo che sia
remote tracking, così il pull successivo lascia sul
disco un sorgente localmente modificato con una storia di modifiche
erronea e tutti gli identificativi dei commit remoti
modificati, in quanto applicati ad una base di codice diversa. A volte
questa operazione genera conflitti nei file, ma invece di non poter
applicare le modifiche locali alla nuova versione ufficiale, non riesce
ad applicare le modifiche ufficiali sulla versione personalizzata.
Anche
in questo caso l'impostazione di git offre una soluzione
relativamente semplice: si può rinominare il ramo e rifare il
fetch o il pull del ramo remoto: poiché gli oggetti
remoti sono già stati scaricati, l'operazione ricreerà un ramo
remote tracking
conforme a quello ufficiale senza ritrasferire tutti i dati.
Il ramo rovinato può poi essere rimosso oppure può essre usato per ripescare
dalla sua storia le modifiche effettuate localmente e riapplicarle ad
un nuovo ramo locale, tramite cherry-pick.
Scambio di codice attraverso la posta elettronica
Dopo aver riordinato il proprio lavoro per renderlo presentabile,
aver fatto un rebase sull'ultima versione e aver risolto eventuali
conflitti,
il passo successivo è normalmente la pubblicazione inviando il proprio
contributo ai manutentori. Il comando
"git format-patch" crea nella directory corrente un file
per ogni commit a partire dalla versione indicata fino allo
stato attuale del codice. Il nome di tali file inizia con un numero
sequenziale di 4 cifre, per poterli concatenare con un
semplice cat.
I file creati da git format-patch sono strutturati come
messaggi di posta elettronica, completi di intestazioni; in base alle
opzioni usate, i messaggi possono avere tutte le informazioni
necessarie ad essere riconosciuti come thread una volta inviati.
Per contribuire il proprio lavoro alle liste di discussione del
pacchetto su cui si è lavorato basta perciò inviare questi messaggi. Se il
proprio programma di posta elettronica modifica i messaggi in modi non
previsti (molti programmi moderni hanno il vizio di spezzare le righe
lunghe o incapsulare il testo in codifiche MIME diverse
da text/plain), è possibile usare git send-email per
l'invio diretto, ma questo presuppone una configurazione ulteriore
di git, che va istruito riguardo alle modalità di invio.
da usare.
Dall'altro lato della rete, chi si trova a dover applicare ai
propri sorgenti una o più patch ricevute tramite posta
elettronica deve semplicemente usare il comando git am (apply
mailbox). L'operazione applica la patch e riproduce i
commenti nel ramo su cui viene invocato, preservando l'autore e le
attribuzioni dell'originale. Se la base di codice di partenza non è
la stessa, il programma applicherà la patch con gli stessi
limiti del comando patch, non avendo a disposizione tutta la
storia per effettuare un 3-way merge. In caso di conflitto,
normalmente si scarta il contributo e si invia al mittente un
freddo messaggio "please rebase and resubmit".
Poiché git format-patch può riconoscere se i file sono stati
rinominati o se un file di nuova creazione è stato copiato da un altro
e poi modificato solo leggermente, indicando questa situazione nel
suo output, non sempre il comando patch
può fare lo stesso lavoro di git am. In assenza di
cambi di nome o copie di file le descrizioni delle differenze
hanno lo stesso formato,
mentre in questi casi particolari le patch in
formato git risultano più compatte e più leggibili di quelle in
formato
diff/patch; almeno fino a quando non verrà aggiunta
un funzionalità equivalente a questi due comandi.
Uso di dati condivisi
Un problema comunemente sentito quando si lavora con git è
la mole dei dati che occorre conservare in ogni cartella di lavoro.
Per esempio, la mia directory di busybox contiene 18MB
di sorgenti e 20MB in .git. Mentre
i sorgenti posso comprimerli in 2.5MB, i 20MB di git sono già
compressi e non si possono ridurre.
Appena una persona lavora contemporaneamente su più rami, per
esempio perché sta seguendo diversi progetti o diversi casi d'uso
dello stesso pacchetto software, risulta comodo
avere diverse cartelle con alberi
git sullo stesso progetto, per non dover continuamente cambiare
ramo e ricompilare di conseguenza tutto. In questa situazione
la mole della storia comune
del progetto inizia a diventare ingombrante, sia sul disco di lavoro
sia sui dispositivi di backup. Naturalmente la quasi totalità
degli oggetti git è ripetuta nelle varie cartelle, perché la storia
passata del pacchetto software è la stessa e le differenze locali sono
di solito poca cosa.
Per evitare la duplicazione di dati, git permette di
specificare archivi alternativi di oggetti, chiamati
alternates. Gli archivi alternativi vengono letti ma non vengono
mai scritti: i commit avvengono sempre localmente.
Tali locazioni si possono indicare nella variabile di ambiente
GIT_ALTERNATE_OBJECT_DIRECTORIES o nel file
.git/objects/info/alternates nella directory del
progetto.
La mia scelta personale, per i lavori che faccio sul kernel, è di
tenere un archivio git contenente solo i rami che scarico
dalla rete, nel quale eseguo fetch periodicamente. I vari
lavori in corso risiedono in alberi git che fanno
riferimento al quest'ultimo come alternate. Devo comunque
invocare git fetch in ciascuno dei progetti,
in quanto lo stato dei
vari rami è memorizzato all'interno del .git locale, ma in
questi archivi di progetto il fetch troverà oggetti già presenti nella
cartella di alternates e non farà una copia locale dei dati
relativi al pacchetto ufficiale. In realtà negli archivi di progetto
perferisco fare fetch dall'altra cartella sulla stessa macchina,
per non rischiare di scaricare dati nel posto sbagliato se nel frattempo
gli autori del pacchetto hanno pubblicato nuove patch.
Procedendo in questo modo si evita una notevole duplicazione di
dati, le cartelle .git di ogni progetto occupano pochi
megabyte di spazio e addirittura si può fare il backup
della sola cartella .git senza i sorgenti,
in quanto tutta la struttura dei
sorgenti può essere estratta in ogni momento con un'operazione di
checkout.
Per evitare di perdere involontariamente pezzi di lavoro, inoltre,
ho creato un archivio git ulteriore, sempre usando alternates per
i rami ufficiali. In questo archivio sposto tutti i rami che non
mi servono più (con un fetch all'interno della stessa macchina)
prima di cancellarli dagli archivi
di progetto. In questo modo ho comunque una copia locale del mio storico,
senza lasciare i rami secchi nelle directory di lavoro e senza
sprecare troppo spazio per conservare tale storico.
Figura 1 - gitk
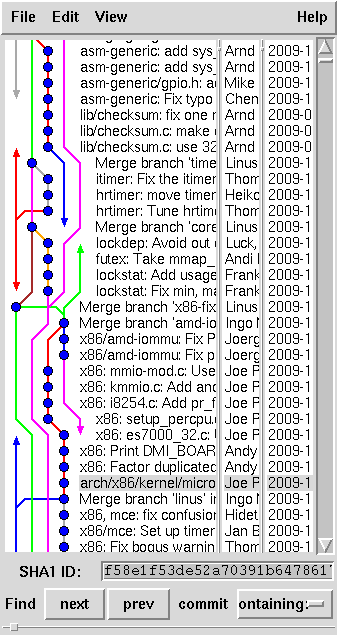
Oltre alla riga di comando, che comunque rimane lo strumento principe
per gli sviluppatori, esistono anche diversi strumenti grafici per
git, utili per meglio capire come se è evoluta la storia di
un progetto e navigare tra i vari rami di sviluppo del codice.
La figura mostra una finestra molto rimpicciolita di gitk
(scritto in Tcl/Tk); un altro approccio quello di gitweb,
spesso installato nei server che offrono sorgenti tramite git.
Approfondimenti
Il pacchetto viene fornito con una documentazione abbastanza
esaustiva, sotto forma di pagine di manuale (comando man). Per
ogni sottocomando di git c'è una pagina di manuale il cui nome
inizia con git-, per esempio "man git-fetch".
Questa convenzione da un lato rispecchia il fatto che inizialmente
ogni sottocomando era un comando a parte, dall'altro permette di
dividere in maniera fruibile una mole di documentazione
che non lo sarebbe se raggruppata un una sola pagina di
manuale. La pagina "git" è comunque fornita, con indicazioni
generali.
Un documento più introduttivo, pensato per iniziare,
è gittutorial(7) (ovvero, la pagina chiamata
gittutorial nel capitolo 7), seguito da
gittutorial-2(7), più approfondito. Altre pagine di
manuale simili sono indicate nella sezione SEE ALSO della
pagina git(1).
Il sito ufficiale del progetto è git.or.cz, e
contiene tra le altre cose un interessante «git per gli utenti svn»
e altri "corsi" in http://git.or.cz/course/.
Il video http://www.youtube.com/watch?v=4XpnKHJAok8 è
una registrazione di Linus Torvalds che parla di git con
i tecnici di Google. È
più a livello di chiacchierata che di presentazione tecnica,
ma risulta comunque interessante.
Il riquadro 5
indica brevemente altri sottocomandi di git
che avrei voluto descrivere perché utili o interessanti; si tratta di
strumenti comunque spiegati nei vari documenti introduttivi sull'uso
del programma.
Riquadro 5 - Altri sottocomandi importanti
Questi son altri comandi git qui non trattati, che consiglio
di studiare a chi volesse usare realmente il programma. Alcuni sono
già stati citati nel riquadro 1.
- merge: riunisce due rami. Non è come rebase perché
non genera nuovi oggetti commit ma incorpora quelli già
realizzati nel ramo corrente. Normalmente usato dai coordinatori di
progetto e non da noi umani.
- pull: fetch e merge insieme: molti documenti
lo indicano come metodo preferenziale per scaricare rami esterni.
Sicuramente per i manutentori è lo strumento giusto; da semplice
utente preferisco fetch perché non consente errori, come
indicato nel testo.
- push: chi mantiene un albero git pubblicato su Internet
usa questo comando per "spingere" il suo ramo di sviluppo verso l'archivio
pubblicato.
- bisect: ausilio utilissimo per trovare l'origine di una
regressione nel codice, quando una versione precedente funzionava ma
la più recente non funziona più.
- blame: quivalente più colorito del comando annotate
presente su altri sistemi di gestione versioni,
mostra un file con le annotazioni su ogni riga.
Si può così sapere autore data e commit che hanno introdotto
una specifica parte di codice.