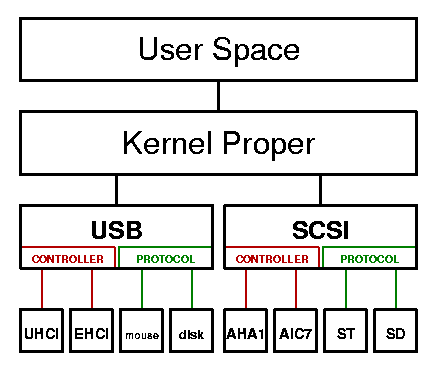
Figura 1
La struttura ideale ad albero
La figura è anche disponibile in PostScript
di Alessandro Rubini
Riprodotto con il permesso di Linux Magazine, Edizioni Master.
In queste pagine si descrivono alcuni aspetti della fase finale dell'avvio del kernel Linux-2.6, quella che avviene in init/main.c
Figura 1
La struttura ideale ad albero
La figura è anche disponibile
in PostScript
Un kernel Linux moderno è un oggetto abbastanza complesso. Gran parte di questa complessità dipende dalla quantità di differenti realtà che devono convivere nella stessa base di codice: processori diversi, macchine diverse (anche quando montano lo stesso processore), protocolli di rete diversificati, bus di comunicazione di vario tipo. Il codice è stato strutturato ordinatamente in "sottosistemi", ognuno dei quali offre funzionalità di alto livello alle varie istanze del codice di più basso livello che deve parlare con le specifiche periferiche.
Per esempio, il sottosistema USB implementa il protollo di
comunicazione del bus, l'inserimento e la rimozione a caldo delle
periferiche, la gestione delle situazioni di errore; il tutto
associato ad un'interfaccia verso il basso per permettere ai driver
associati al singolo dispositivo USB di integrarsi dinamicamente
nell'architettura software. Inoltre il sottosistema definisce
un'interfaccia di basso livello verso i "controllori" USB, in modo che
l'implementazione del protocollo si possa appoggiare su diverse
implementazioni hardware. Altri sottosistemi del kernel sono SCSI,
IDE, PCI, come pure sottosistemi puramente software, per esempio la
gestione dei dati in ingresso (drivers/input).
Idealmente, ogni sottosistema ospita una o più classi di moduli di più basso livello, in una struttura ad albero, in cui le istanze dei dispositivi, o dei controllori appartengono ad un unico sottosistema, come mostrato in figura 1. In molti casi, però i driver di livello inferiore devono comunicare con più sottosistemi. Per esempio i controllori SCSI e USB sono spesso periferiche PCI e un disco USB viene visto come una periferica SCSI, come rappresentato in figura 2.
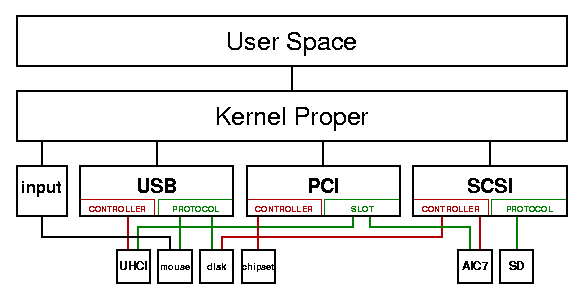
Figura 2
La struttura reale dei sottosistemi
La figura è anche disponibile
in PostScript
Uno dei problemi da affrontare nel progetto di sistemi variamente interconnessi come quello descritto è quello dell'avvio. Mentre l'aggiunta di un modulo a sistema avviato non pone problemi poiché tutte le componenti del suo ambiente operativo sono già disponibili, l'avvio del kernel può avvenire solo se i sottosistemi vengano attivati nell'ordine corretto.
Sempre riferendosi alla figura 2, non è possibile attivare il disco USB se non sono già stati attivati i sottosistemi SCSI e USB, il sottosistema PCI per poter comunicare con il controllore USB e il modulo scsi-disk per il protocollo di comunicazione verso il disco.
Versioni precedenti di Linux usavano un approccio piuttosto
semplicistico per l'inizializzazione,
sicuramente adatto ad un sistema con pochi componenti
ma non più facilmente manutenibile con l'enorme crescita delle
periferiche supportate. Originariamente l'inizializzazione del sistema
consisteva nella chiamata sequenziale delle funzioni di
inizializzazione dei vari moduli, nell'ordine in cui erano inseriti
nel codice sorgente, spesso protetti da serie di #ifdef. Con
l'introduzione di <linux/init.h> si è permesso ad ogni modulo di
dichiarare le sue funzioni di inizializzazione, automatizzando la loro
esecuzione. Purtroppo però il corretto avvio del sistema dipendeva in
ancora in modo oscuro dall'ordine in cui i file apparivano nelle
regole del Makefile; spostare un file o aggiungere un nuovo file
nella posizione sbagliata poteva rendere impossibile il boot, così
come avrebbe potuto essere impossibile compilare il codice attuale con
versioni successive del compilatore.
initcallsPer evitare la lunga lista di chiamate alle varie funzioni di inizializzazione dei vari sottosistemi e driver abilitati nel kernel, gli sviluppatori sono ricorsi all'uso di sezioni ELF speciali, come abbiamo già visto fare per la gestione della modularizzazione.
La funzione di inizializzazione di ogni driver, oltre ad essere
inserita nella sezione .init.text (di cui abbiamo già parlato nel
numero di Febbraio), viene dichiarata come initcall in modo che un
suo puntatore venga inserito in una apposita sezione ELF. Durante
l'avvio del sistema, la funzione do_initcalls (in init/main.c)
scorre la lista di tali puntatori per invocare tali funzioni. Una
initcall per un ipotetico driver ipot viene scritta nel seguente
modo:
__initcall(ipot_init)
#include <linux/init.h>
int __init ipot_init(void)
{ /* ... */ }
Il file <linux/init.h> ora definisce sette diverse classi di
initcall:
#define core_initcall(fn) __define_initcall("1",fn)
#define postcore_initcall(fn) __define_initcall("2",fn)
#define arch_initcall(fn) __define_initcall("3",fn)
#define subsys_initcall(fn) __define_initcall("4",fn)
#define fs_initcall(fn) __define_initcall("5",fn)
#define device_initcall(fn) __define_initcall("6",fn)
#define late_initcall(fn) __define_initcall("7",fn)
__initcall è ancora valida ed è
equivatente a device_initcall.
Il puntatore ad ogni funzione viene inserito in una sezione ELF
specifica, chiamata, per esempio, .initcall6.init . L'ordinamento
relativo delle varie chiamate viene garantito dal linker script usato
per creare vmlinux, cioè vmlinux.lds.S per ciascuna piattaforma,
che prescrive la creazione di un'unica sezione .initcall.init
che contenga, in ordine numerico, le sette sezioni presenti nei
file oggetto di ingresso al linker:
__initcall_start = .;
.initcall.init : {
*(.initcall1.init)
*(.initcall2.init)
*(.initcall3.init)
*(.initcall4.init)
*(.initcall5.init)
*(.initcall6.init)
*(.initcall7.init)
}
__initcall_end = .;
__initcall_start e __initcall_end
identificano gli estremi della sezione nel file vmlinux e vengono
usati per accedere al vettore di puntatori in do_initcalls.
Lo stesso meccanismo di initcall può venire usato per gestire
ordinatamente l'interpretazione degli argomenti sulla linea di comando
del kernel. La dichiarazione __setup, mostrata nel riquadro in
questa pagina insieme ad una versione semplificata del codice di
do_initcalls, inserisce informazioni in una sezione ELF chiamata
.init.setup.
Riquadro 1 - do_initcalls e __setup
|
L'interpretazione degli argomenti sulla linea di comando del kernel appena introdotta è un'altra funzionalità molto importante per un corretto avvio del sistema.
Nonostante init/main.c usi __setup per dichiarare alcuni
parametri, come quiet e debug di cui si è parlato il mese
scorso, si tratta del meccanismo di Linux-2.4, oggi considerato
obsoleto, a favore di quello definito in <linux/moduleparm.h>.
Il nuovo meccanismo è più pesante del precedente a livello di implementazione, ma più leggero da usare. Inoltre permette di unificare, a livello di codice sorgente, il passaggio di un parametro ad un modulo caricato dinamicamente, il passaggio dello stesso parametro al driver staticamente incluso nell'immagine del kernel e la modifica del parametro durante il funzionamento del sistema (ma questa funzionalità non è ancora disponibile).
Per il programmatore, la dichiarazione di un parametro configurabile
si riduce ad una riga di codice. Il kernel contiene già al suo
interno il supporto per la lettura e scrittura dei tipi fondamentali
e delle stringhe (usando il nome charp come tipo),
oltre a vettori di tipi fondamentali e stringhe.
Per esempio, se l'ipotetico modulo ipot avesse un parametro stringa e uno intero leggibile da tutti e modificabile a run-time dal solo amministatore di sistema conterrebbe le seguenti righe:
char *ipot_name;
module_param(ipot_name, charp, 0);
int ipot_param;
module_param(ipot_param, int, S_IRUGO|S_IWUSR);
Trascurando il caso dei vettori, che si differenzia leggermente, la nuova
implementazione si basa su struct kernel_param, una struttura dati
che contiene oltre al nome, al puntatore al parametro e ai permessi di
accesso, anche i puntatori a due funzioni usate per converire il
parametro dalla sua forma testuale a quella interna e viceversa.
Le conversioni sono definite in kernel/params.c;
il scondo argomento passato a module_param permette di identificare
la coppia di funzioni da inserire nella struttura dati.
Le strutture kernel_param vengono raccolte
in una sezione ELF apposita, chiamata __param e recuperate
al boot tramite due simboli definiti nel linker script, come
già visto per initcalls.
Poiché i parametri dinamici devono essere assegnati prima
dell'inizializzazione di un sottosistema o di un driver, la funzione
parse_args ( definita in kernel/params.c) viene chiamata nella
parte iniziale di start_kernel. Quando parse_args trova
un parametro che non e` definito nel vettore di strutture dati, utilizza un
puntatore unknown come soluzione di ripiego. Tale
soluzione, chiamata __unknown_bootoption e definita in init/main.c,
cerca il parametro nella sezione .init.setup, in modo da continuare a
supportare il meccanismo di dichiarazione dei parametri di Linux-2.4; i
parametri che non vengono riconosciuti nemmeno in questo modo
diventano variabili di ambiente
o opzioni sulla riga di comando del processo init, come è sempre
stato per gli argomenti di linea di comando non riconosciuti dal kernel.
Se un parametro dichiarato con module_param deve essere leggibile
o scrivibile durante la vita della macchina, il sistema lo dovrebbe
rendere accessibile tramite un file all'interno di sysfs, un
filesystem virtuale, come /proc, che normalmente viene montato sulla
directory /sys, ma le versioni attuali di Linux-2.6 non rendono visibili
i parametri in sysfs.
L'implementazione di questa funzionalità dovrà in ogni caso
richiedere una seconda iterazione sulla sezione param in un
momento più avanzato dell'inizializzazione del kernel, dopo la
creazione della struttura di sysfs che avviene nella
funzione driver_init, chiamata verso la fine della procedura
di avvio. Sarà anche necessario associare i parametri allo
specifico oggetto cui appartengono, associazione che non è
realizzata dalla struttura kernel_param come definita ora.
sysfs e la definizione di parametri modificabili a run-time
(parametri diversi da quelli che appaiono nella linea di comando
del kernel) saranno l'argomento di uno dei prossimi articoli.